linux 基础
参考:
基本概念¶
操作系统¶
计算机是一台机器,它按照用户的要求接收信息、存储数据、处理数据,然后再将处理结果输出(文字、图片、音频、视频等)。计算机由硬件和软件组成:
- 硬件是计算机赖以工作的实体,包括显示器、键盘、鼠标、硬盘、CPU、主板等;
- 软件会按照用户的要求协调整台计算机的工作,比如 Windows、Linux、Mac OS、Android 等操作系统,以及 Office、QQ、微信等应用程序。
操作系统(Operating System,OS)是软件的一部分,它是硬件基础上的第一层软件,是硬件和其它软件沟通的桥梁。
操作系统会控制其他程序运行,管理系统资源,提供最基本的计算功能,如管理及配置内存、决定系统资源供需的优先次序等,同时还提供一些基本的服务程序。
Linux历史¶
- 1970年,Unix 诞生于贝尔实验室,开放源码,此后诞生了AIX、Solaris、HP-UX、BSD等Unix系统
- 1979年,从Unix V7开始,贝尔实验室严格了版本 ,禁止其源码用于教学
- 1987年,Tanenbaum 发布了其从头开发、兼容Unix V7的操作系统 Miniux(mini-UNIX)用于教学
- 1991年,Minix功能有限,Linus借鉴Minix开发了Linux(内核)
- 1983年,Stallman发起GNU(GNU is not Unix)计划,目标是创建一套完全自由的操作系统,并陆续开发了Emacs、GCC等各种工具,但缺乏操作系统内核
- 1991年Linus开发出Linux内核之后,GNU软件和Linux内核结合, 形成现代Linux生态环境。Stallman发布的GPL协议保障了开源软件的发展。
根据不同目的和用途,整合Linux内核和各类应用软件形成不同的操作系统,称之为Linux发行版。常见的Linux发行版有Ubuntu、Dedian、RHEL、Fedora、CentOS、SLE等。
Linux特点¶
- 免费
- 一切皆文件
- 由目的单一的小程序组成,组合小程序完成复杂任务
- 多任务、多用户系统
- 大量的可用软件
- 良好的可移植性及灵活性
- 优秀的稳定性和安全性
Linux组成¶
- Kernel(内核)
- 系统启动时将内核装入内存
- 管理系统各种资源
- Shell
- 保护操作系统
- 用户界面,提供用户与内核交互处理接口,各种命令运行的地方
- bash, ash, pdksh, tcsh, ksh, sh, csh, zsh….
- Utility
- 提供各种管理工具,应用程序
文件¶
linux哲学核心思想是"一切皆文件"。"一切皆文件"指的是,对所有文件(目录、字符设备、块设备、套接字、打印机、进程、线程、管道等)操作,读写都可用 fopen()/fclose()/fwrite()/fread() 等函数进行处理。屏蔽了硬件的区别,所有设备都抽象成文件,提供统一的接口给用户。虽然类型各不相同,但是对其提供的却是同一套操作界面。
文件具有多种属性,如类型、所属用户、用户组、权限、修改时间、大小等。
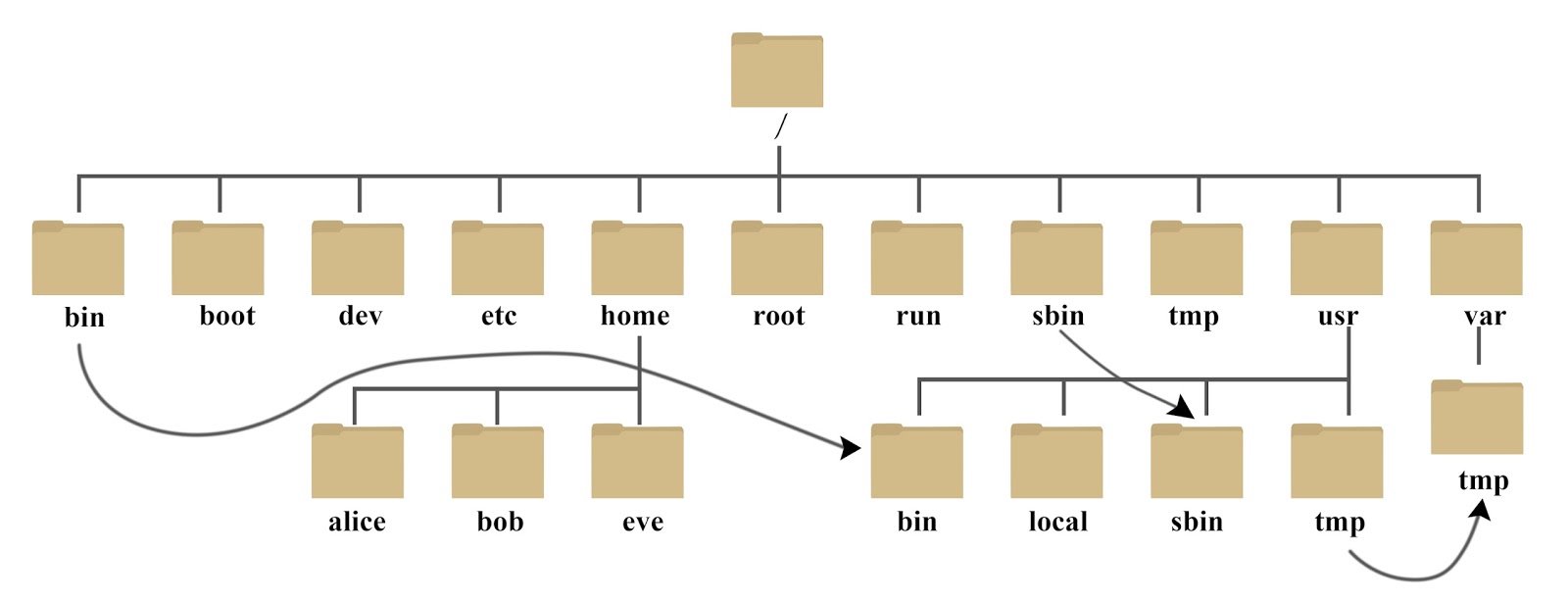
所有文件的起始为 / (根目录),采用树形结构存放。各类文件存放目录遵循FHS (Filesystem Hierarchy Standard)。
文件的位置称之为路径,如 /var/log/messages。
- 从
/写起的为绝对路径,如/var/log/messages - 从当前位置写起的为
相对路径,如log/messages
https://www.runoob.com/wp-content/uploads/2014/06/d0c50-linux2bfile2bsystem2bhierarchy.jpg
{kind=link}
/
├── bin # binaries(二进制文件),存放着最常用的程序和指令
├── boot # 系统启动相关文件,如内核,initrd,以及grub(BootLoader)
├── dev # device,设备文件 — 体现了LInux的“一切皆文件”思想
├── etc # 配置文件。大多数为纯文本文件
├── home # 用户的家目录
├── lib # library,公共库文件(不能单独执行, 只能被调用)
├── media # 挂载点目录,挂载移动设备(如U盘)
├── mnt # 挂载额外的临时文件(如第二块硬盘)
├── opt # optional,存放额外安装软件
├── proc # processes,伪文件系统,内存映射文件,系统启动后才出现文件, 关机就空
├── root # 管理员的家目录
├── run # 是一个临时文件系统,存储系统启动以来的信息
├── sbin # superuser binaries,存放系统管理所需要的命令
├── srv # 该目录存放一些服务启动之后需要提取的数据
├── tmp # temporary,临时文件,所有用户都可以操作,但只能删自己的,不能删别人的
├── usr # unix shared resources,存放只能读的命令和其他文件
└── var # variable,存放运行时需要改变数据的文件,如日志等
用户和用户组¶
多个用户可以在同一时间内登录同一个Linux系统执行各自不同的任务,互不影响。每个用户有唯一的用户名、用户id(uid),并通过各自的密码登录使用,每个用户不能干涉其它用户的活动、访问修改其它用户的文件。
root用户(超级用户)拥有系统最高权限。
用户组是具有相同特征用户的逻辑集合。有时需要让多个用户具有相同的权限,比如查看、修改某一个文件的权限等,通过用户组可以方便地实现。将用户分组是Linux 系统中对用户进行管理及控制访问权限的一种手段,通过定义用户组,简化了管理工作。每个用户组有唯一的名称和id(gid)。
用户和用户组的对应关系有:
- 一对一:即一个用户可以存在一个组中,也可以是组中的唯一成员
- 一对多:即一个用户可以存在多个用户组中。那么此用户具有多个组的共同权限
- 每个用户拥有唯一的主用户组(primary group)
- 每个用户可以拥有多个附加用户组(supplementary groups)
- 多对一:多个用户可以存在一个组中,这些用户具有和组相同的权限
- 多对多:多个用户可以存在多个组中。其实就是上面三个对应关系的扩展
权限¶
在Linux中,多用户之间通过权限实现资源的隔离和共享,以保障整个系统的安全。权限的主体为用户,对象为文件。用户对自己的文件有绝对的权限,本用户的文件默认禁止其它用户访问,可通过更改文件权限向其它用户共享特定文件,使其它用户可以访问和修改该文件。
root用户对所有文件拥有访问和修改的权限。
命令¶
命令(command)是在命令行上运行的程序或实用程序。命令行(CLI, command line interface),是一种命令提示符界面,它接受文本行并将其处理为计算机的指令。
命令提示符(prompt):登陆成功后显示的东西,如[username@localhost ~]$ ,其中 #:root用户,$:普通用户。
命令格式: 命令 -选项 参数
- 命令:shell传递给内核,并由内核判断该程序是否有执行权限,以及是否能执行,从什么时候开始执行
- 选项(options):命令所含的一些选项,通过选项控制命令的细节行为(可选,非必须)
- 短选项:
-character,多个选项可以组合 ,可以写ls -l -a或者ls -la - 长选项:
–word,不能组合,要分开
- 短选项:
- 参数(arguments),多数用于指向命令的指向目标(可选,非必须),多个参数要用空格隔开,参数顺序决定命令的作用顺序
命令类型:
- 内置命令(shell builtin 内置)
- 外部命令:某个路径下有一个与命令名称相应的可执行文件
命令补全:使用 tab键 补全功能,可提升输入效率,减少输入错误
- 命令补全:tab 接在一串指令的第一个字的后面
- 文件补全:tab 接在一串指令的第二个字以后时
命令历史:shell会记录执行过的命令,退出后写入~/.bash_history。使用history 命令查看使用过的命令
↑和↓可以上下翻看使用过的命令ctrl + r输入字符,可以快速定位到使用过的命令
命令帮助:man 命令 打开命令手册信息,包含命令的详细用法及各选项解释;命令 -h 显示命令用法
命令存放在$PATH的路径中,命令执行时会在这些路径中逐一搜索,并执行第一个搜索的命令。可以使用绝对路径准确执行命令。
$ echo $PATH
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin
命令行常用快捷键:
ctrl+a:跳到命令行首
ctrl+e:跳到命令行尾
ctrl+u:删除光标至命令行首的内容, 命令行下清除输错的密码很管用
ctrl+k:删除光标至命令行尾的内容
ctrl+l:清屏
文件操作¶
文件属性¶
$ ls -lh
total 3.0K
drwxr-xr-x 2 username usergroup 4.0K Sep 17 2020 code
drwxr-xr-x 5 username usergroup 4.0K Sep 23 2020 data
drwxr-xr-x 2 username usergroup 4.0K Sep 6 2019 data2
-rw-r--r-- 1 username usergroup 50 May 18 09:09 file
drwxr-xr-x 2 username usergroup 4.0K Sep 6 2016 MPI
drwxr-xr-x 14 username usergroup 4.0K Jun 3 2019 software
- 第一字段:文件类型;
- 第二字段:文件访问权限;
- 第三字段:硬链接个数;
- 第四字段:属主(owner),拥有该文件或目录的用户账号;
- 第五字段:所归属的组(group),拥有该文件或目录的组账号;
- 第六字段:文件或目录的大小, 默认单位 bytes;
- 第七字段:最后访问或修改时间;
- 第八字段:文件名或目录名
文件类型¶
linux中文件后缀不能表示文件类型,只是方便识别
| 类型 | 简称 | 描述 |
|---|---|---|
| 普通文件 | -,Normal File | 如mp4、pdf、html log;用户可以根据访问权限对普通文件进行查看、更改和删除,包括 纯文本文件(ASCII);二进制文件(binary);数据格式的文件(data);各种压缩文件.第一个属性为 - |
| 目录文件 | d,directory file | /usr/ /home/,目录文件包含了各自目录下的文件名和指向这些文件的指针,打开目录事实上就是打开目录文件,只要有访问权限,就可以随意访问这些目录下的文件。能用 cd 命令进入的。第一个属性为 d,例如 drwxrwxrwx |
| 硬链接 | -,hard links | 若一个inode号对应多个文件名,则称这些文件为硬链接。硬链接就是同一个文件使用了多个别名删除时,只会删除链接, 不会删除文件;硬链接的局限性:1.不能引用自身文件系统以外的文件,即不能引用其他分区的文件;2.无法引用目录; |
| 符号链接(软链接) | l,symbolic link | 若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接,克服硬链接的局限性, 类似于快捷方式,使用与硬链接相同 |
| 字符设备文件 | c,char | 文件一般隐藏在/dev目录下,在进行设备读取和外设交互时会被使用到,即串行端口的接口设备,例如键盘、鼠标等等。第一个属性为 [c]。/dev/tty 的属性是 crw-rw-rw-,前面第一个字 c,这表示字符设备文件 |
| 块设备文件 | b,block | 存储数据以供系统存取的接口设备,简单而言就是硬盘。/dev/hda1 的属性是 brw-r—– ,注意前面的第一个字符是 b,这表示块设备,比如硬盘,光驱等设备。系统中的所有设备要么是块设备文件,要么是字符设备文件,无一例外 |
| FIFO管道文件 | p,pipe | 管道文件主要用于进程间通讯。FIFO解决多个程序同时存取一个文件所造成的错误。比如使用 mkfifo 命令可以创建一个FIFO文件,启用一个进程A从FIFO文件里读数据,启动进程B往FIFO里写数据,先进先出,随写随读。 |
| 套接字 | s,socket | 以启动一个程序来监听客户端的要求,客户端就可以通过套接字来进行数据通信。用于进程间的网络通信,也可以用于本机之间的非网络通信,第一个属性为 [s] ,这些文件一般隐藏在 /var/run 目录下,证明着相关进程的存在 |
日常使用中接触最多的为普通文件、目录文件、软连接,其中对于普通文件而言,根据其可读性可分为文本文件(ASCII text)、其它文件等。
文本文件类似于windows下的txt文件,可以使用文本操作命令 cat less 等直接读取,如各种序列文件、C源代码、程序脚本等;
其它文件有各类命令、压缩文件等,一般不可直接读取,直接 cat 读取会显示为乱码。
一般使用 file 命令可以查看普通文件的类型:
# 显示ASCII text为文本文件
$ file IRGSP-1.0_genome.fasta
IRGSP-1.0_genome.fasta: ASCII text
# C代码源文件也是ASCII text,即文本文件
$ file hello.c
hello.c: C source, ASCII text
# shell脚本也是ASCII text,即文本文件
$ file hello.sh
hello.sh: POSIX shell script, ASCII text executable
# python脚本也是ASCII text,即文本文件
$ file test.py
test.py: a /bin/python script, ASCII text executable
# 这种为ELF文件,即Linux中的可执行文件,一般为C/C++编译后生成
$ file /bin/ls
/bin/ls: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=c5ad78cfc1de12b9bb6829207cececb990b3e987, stripped
# gzip压缩文件
$ file HW84_NDSW31815_1.clean.fq.gz
HW84_NDSW31815_1.clean.fq.gz: gzip compressed data, was "NDSW31815_NDSW31815_1.clean.fq", from Unix, last modified: Fri Jul 6 16:17:47 2018
# 可以看到bam文件也是一种gzip压缩文件
$ file HW84_NDSW31815_sorted.bam
HW84_NDSW31815_sorted.bam: gzip compressed data, extra field
访问权限¶
文件属性的权限字段中,有9个字符,3个字符一组,共三组,分别代表属主(u, user)、属组(g, group)、其它人(o, other)的权限;
每组权限字符中,从第一位到第三位分别为下面4个字符中的一个:
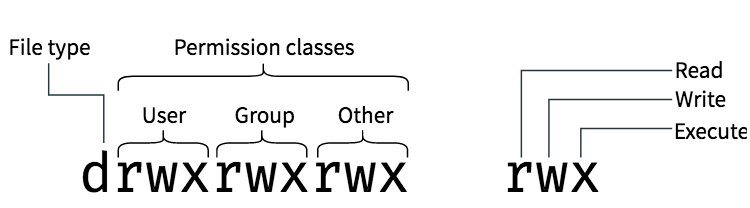
图片来源 booleanworld.com
文件和目录的权限作用不同;
- 读取(r, read): 允许查看文件内容;允许
ls显示目录列表。数字表示为4, - 写入(w, write): 允许修改文件内容;允许在目录中新建、删除、移动文件或者子目录。数字表示为2
- 可执行(x, execute): 允许运行程序;允许
cd进入目录。数字表示为1 - 无权限(-): 没有权限,数字表示为0
| 类型 | r | w | x |
|---|---|---|---|
| 文件 | 读取文件内容 | 修改文件内容 | 执行文件内容 |
| 目录 | 读取文件列表 | 修改文件或目录 | 进入该目录的权限 |
为方便表示,每组权限字符的3个数字表示可以相加
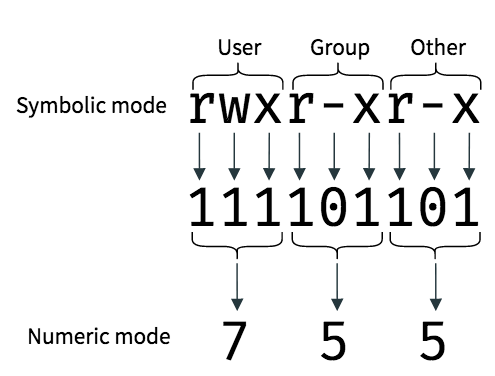
图片来源 booleanworld.com
如 rwxr-xr-x 可以表示为 4+2+1=7,4+1=5, 4+1=5,即755
文件扩展名¶
linux 文件扩展名无特殊意义,一般用于标识文件内容,如:
- .sh:shell脚本
- Z、.tar、.tar.gz、.zip、.tgz:经过打包的压缩文件。不同的压缩软件压缩的扩展名不同如,gunzip、tar
- .html、.php:网页相关文件
- .pl、.py: Perl、Python 脚本
常用命令¶
- ls 列出文件,-a -h -l -t -r –d
- tree 以树形列出文件
- cd 切换目录 cd; cd ~; cd -; cd ..; cd ../..
- pwd 显示当前目录
- mkdir 创建目录, -p
- rm 删除文件 –r
- mv 移动文件或者重命名文件
- cp 复制文件 –r
- touch 创建空文件或更新文件时间
- rename 文件重命名, 支持正则 rename fasta fa *.fasta
- find 查找文件, -name -type –size
- which 查找可执行文件的绝对路径
- ln 创建链接 –S 删除软链接时要特别小心
- du 显示文件和目录的磁盘使用情况 -sh
- chmod 更改文件权限 755 -R
- tar 文件目录压缩、解压 –xf file.tgz; -zcvf file.tgz file; -tvf file.tgz
- gzip 文件压缩、解压 –d, 推荐 pigz, 支持多线程
# 列出 ~/training 目录内的文件
$ ls ~/training
code data data2 file MPI software
# -a, 列出 ~/training 目录内的所有文件,包含隐藏文件
$ ls -a ~/training
. .. code .config data data2 file MPI software
# -l, 以长格式显示目录下的内容列表, 日常使用可以使用ll代替ls -l。
# 输出的信息从左到右依次包括文件名,文件类型、权限模式、硬连接数、所有者、组、文件大小和文件的最后修改时间等
$ ls -l ~/training
total 3
drwxr-xr-x 2 username usergroup 4096 Sep 17 2020 code
drwxr-xr-x 5 username usergroup 4096 Sep 23 2020 data
drwxr-xr-x 2 username usergroup 4096 Sep 6 2019 data2
-rw-r--r-- 1 username usergroup 50 May 18 09:09 file
drwxr-xr-x 2 username usergroup 4096 Sep 6 2016 MPI
drwxr-xr-x 14 username usergroup 4096 Jun 3 2019 software
# -h, 打印大小,K表示千字节,M表示兆字节,G表示吉字节
$ ll -h
total 3.0K
drwxr-xr-x 2 username usergroup 4.0K Sep 17 2020 code
drwxr-xr-x 5 username usergroup 4.0K Sep 23 2020 data
drwxr-xr-x 2 username usergroup 4.0K Sep 6 2019 data2
-rw-r--r-- 1 username usergroup 50 May 18 09:09 file
drwxr-xr-x 2 username usergroup 4.0K Sep 6 2016 MPI
drwxr-xr-x 14 username usergroup 4.0K Jun 3 2019 software
#-t, 用文件和目录的更改时间排序
ls -lt
total 3
-rw-r--r-- 1 username usergroup 50 May 18 09:09 file
drwxr-xr-x 5 username usergroup 4096 Sep 23 2020 data
drwxr-xr-x 2 username usergroup 4096 Sep 17 2020 code
drwxr-xr-x 2 username usergroup 4096 Sep 6 2019 data2
drwxr-xr-x 14 username usergroup 4096 Jun 3 2019 software
drwxr-xr-x 2 username usergroup 4096 Sep 6 2016 MPI
# -r, 输出目录内容列表
$ ls -lr
total 3
drwxr-xr-x 14 username usergroup 4096 Jun 3 2019 software
drwxr-xr-x 2 username usergroup 4096 Sep 6 2016 MPI
-rw-r--r-- 1 username usergroup 50 May 18 09:09 file
drwxr-xr-x 2 username usergroup 4096 Sep 6 2019 data2
drwxr-xr-x 5 username usergroup 4096 Sep 23 2020 data
drwxr-xr-x 2 username usergroup 4096 Sep 17 2020 code
# –d, 仅显示目录名,而不显示目录下的内容列表。显示符号链接文件本身,而不显示其所指向的目录列表
# 注意-d和不加-d参数的区别
$ ls -ld software
drwxr-xr-x 14 username usergroup 4096 Jun 3 2019 software
$ ls -l software
total 221717
drwxr-xr-x 5 username usergroup 4096 Sep 6 2016 blast-2.2.31
drwxr-xr-x 5 username usergroup 4096 Sep 6 2016 bowtie2-2.1.0
-rw-r----- 1 username usergroup 15631689 Sep 6 2016 bowtie2-2.1.0-linux-x86_64.zip
drwxrwxr-x 5 username usergroup 4096 Sep 9 2016 bowtie2-2.2.6
drwxr-xr-x 5 username usergroup 8192 Sep 6 2016 hisat2-2.0.4
-rw-r--r-- 1 username usergroup 3875287 Sep 6 2016 hisat2-2.0.4-source.zip
# -f, 不进行排序输出。ls默认会将所有文件名进行排序之后再输出。
# 当目录内文件数据量非常多时,如几千到几万个文件,ls会非常耗时,建议加上-f参数节省时间
$ls -f
. .. .config code MPI software file data data2
# 列出 data2目录下的文件
$ tree data2/
data2/
├── blast.bak.pbs
├── blast.e1692608
├── blast.lsf
├── blast.o1692608
├── blast.pbs
├── example.lsf
├── MH63_cds.fa
├── MH63_cds.nhr
├── MH63_cds.nin
├── MH63_cds.nog
├── MH63_cds.nsd
├── MH63_cds.nsi
├── MH63_cds.nsq
├── prosss.sh
├── ZS97_cds
└── ZS97_cds.fa
0 directories, 16 files
# 从当前目录切换到 '~/app' 目录
$ cd ~/app
# 从任何位置切换回用户主目录 '/home/User'
$ cd
# 回退上一个访问目录
$ cd -
# 返回上一级目录
$ cd ..
# 返回上上一级目录
$ cd ../../
# 使用相对路径,进入另一个目录"new directory",这里 '\' 是转义符,将空格键正确转义
$ cd ../../../new\ directory
# 当不知道当前处于什么路径时,可以用这个命令显示
$ pwd
/public/home/username/training
# 在当前目录下创建新目录 new
$ mkdir new
# -p, 在当前目录下创建多级目录
$ mkdir -p newdir1/newdir2/newdir3/newdir4
$ tree newdir1/
newdir1/
└── newdir2
└── newdir3
└── newdir4
3 directories, 0 files
# 删除普通文件
$ rm file
# 删除当前目录的所有后缀是 '.sra' 的文件
$ rm *.sra
# -r, 参数删除目录
# 删除目录 'new' 以及 'new' 下的所有子文件与子目录
$ rm -r new
# -f, 不弹出删除确认提示,删除所有 '.tmp' 文件
$ rm -f *.tmp
# 将 'file' 改名为 'file1'
$ mv file file1
# 将 'file1' 移动到 'newdir'目录内
$ mv file1 newdir/
# 复制 'file1' 文件到目录 '~/newdir' 中
$ cp file1 ~/new
# -r 复制目录
# 复制 newdir 目录到用户目录下
$ cp -r newdir/ ~
# 创建空文件 'empty.txt'
$ touch emplty.txt
# 方便批量修改文件名
# 将 'seq.fasta' 更名为 'seq.fa'
$ rename seq.fasta seq.fa seq.fasta
# 将所有fasta文件更名为fa
$ rename fasta fa *fasta
# 去掉所有fa文件前缀
$ rename Osativa_323_v7.0.id_ '' *fa
# 查找一个文件,比如 /etc路径下的hosts文件
$ find /etc/ -name hosts
# 查找当前目录及子目录后缀为gz的文件
$ find . -type f -name "*.gz"
# 查找所有的 html 网页文件
$ find . -type f -regex ".*html$"
# 将所有 fasta 文件中序列名字包含node的改成seq
$ find . -type f -regex ".*fasta$" | xargs sed 's/NODE/Seq/g'
# 查找子目录深度为4层目录的fasta文件
$ find . -type f -maxdepth 4 -name "*.fasta"
# 查找/var/log路径下权限为755的目录
$ find /var/log -type d -perm 755
# 按照用户查找用户,在tmp路径下查找属于用户 nginx 的文件
$ find /tmp -user nginx
# 用户主home路径下查找属于 root 权限,属性为644的文件
$ find . -user root -perm 644
# 打印出系统带的 python 程序的路径
$ which python
/bin/python
# 为 '~/ref/ref.fa' 在当前目录下创建软连接
$ ln -s ~/ref/ref.fa ref.fa
# 如果需要软连接与源文件文件名相同,可以如下方式简写
$ ln -s ~/ref/ref.fa .
# 删除软连接时,文件名加了/表示将源文件一并删除,不加/表示只删除当前的软连接
# 删除软连接
$ rm ref.fa
# 删除源文件
$ rm ref.fa/
# 查看data目录的磁盘使用
$ du -sh data
14G data
# home目录下运行下面的命令,查看各目录所占磁盘空间大小
$ du -h --max-depth=1
512 ./Desktop
8.1M ./githup
132K ./.ssh
45M ./perl5
512 ./Videos
u User,即文件或目录的拥有者;
g Group,即文件或目录的所属群组;
o Other,除了文件或目录拥有者或所属群组之外,其他用户皆属于这个范围;
a All,即全部的用户,包含拥有者,所属群组以及其他用户;
r 读取权限,数字代号为“4”;
w 写入权限,数字代号为“2”;
x 执行或切换权限,数字代号为“1”;
- 不具任何权限,数字代号为“0”;
s 特殊功能说明:变更文件或目录的权限;
chmod u/g/o/a +/-/= r/w/x 文件或目录
# 给文件的User加上可执行权限
$ chmod u+x file
# 将目录共享给组用户
$ chmod g+rwx dir
# 取消文件的x权限
$chmod -x file
# 取消 home 目录的共享权限
$ chmod 700 ~
# 查看 home 目录权限
$ ll -d ~
drwx------ 30 username usergroup 8192 Sep 14 10:24 /public/home/username
# 打包压缩
$ tar -czvf data.tar.gz data
# 使用pigz多线程打包压缩,加快打包压缩速度;解压同理
$ tar -cvf data.tar.gz data -I pigz
# 解压
$ tar -xf data.tar.gz
# 使用 pigz 解压
$ tar -I pigz -xf data.tar.gz
# 查看但不解压
$ tar -ztvf
# 压缩文件
$ gzip reads.fq
# -d, 解压文件
$ gzip -d reads.fq.gz
#使用方式与gzip基本一致,-p参数可以使用多线程,加速文件压缩/解压
# 压缩文件
$ pigz -p 4 reads.fq
# 解压文件
$ pigz -p 4 -d reads.fq.gz
# 多线程打包压缩
$ tar cvf - dir | pigz -p 4 >dir.tgz
# 或
$ tar -cvf data.tar.gz data -I pigz
# 使用 pigz 解压 tar.gz 压缩包
$ tar -I pigz -xf data.tar.gz
- wget 下载文件
- scp 远程文件传输
- rsync 文件传输
参考:https://wangchujiang.com/linux-command/c/wget.html
# 下载samtools
$ wget https://github.com/samtools/samtools/releases/download/1.3.1/samtools-1.3.1.tar.bz2
# -c,断点续传
$ wget -c https://github.com/samtools/samtools/releases/download/1.3.1/samtools-1.3.1.tar.bz2
# -b,后台下载
$ wget -b https://github.com/samtools/samtools/releases/download/1.3.1/samtools-1.3.1.tar.bz2
# -o,日志文件
$ wget https://github.com/samtools/samtools/releases/download/1.3.1/samtools-1.3.1.tar.bz2 -o log
# ftp下载,需要用户名和密码
$ wget --ftp-user=USERNAME --ftp-password=PASSWORD url
# ftp 匿名下载,下载目录内所有文件
$ wget -c -r ftp://download.big.ac.cn/gsa/CRA004538
# -i,下载多个文件
$ wget -i filelist.txt
$ cat filelist.txt
url1
url2
url3
url4
# 从本地传到远端
$ scp file user@ip:/dir/
# 从远端传到本地
$ scp user@ip:/dir/file .
# -r,传输目录
$ scp -r dir user@ip:/dir/
# -P,更改默认端口
$ scp -P 12345 file user@ip:/dir/
# -p,保留原文件的修改时间,访问时间和访问权限
$ scp -p file user@ip:/dir/
# 由于rsync在传输时会进行校验,因此当网络不稳定或文件数较多时,
# 可以使用rsync检验文件是否传完,以及跳过已经传输过的文件
# 同步本地目录dir1到本地目录dir2
$ rsync -avP dir1 dir2
# 同步本地目录dir1内的文件到本地目录dir2。注意dir1有无 "/" ,传输的文件有区别
$ rsync -avP dir1/ dir2
# 同步本地目录dir1 到远程目录dir2
$ rsync -avP dir1 user@ip:/dir2/
# 更改默认端口
$ rsync -avP -e 'ssh -P 12345' dir1 user@ip:/dir2/
路径特殊字符¶
| 字 符 | 含 义 |
|---|---|
| ~ | home 目录 |
| - | 代表上一次(相对于当前路径)用户所在的路径 |
| . | 当前目录 |
| .. | 上层目录 |
通配符¶
一次性操作多个文件时,命令行提供通配符(wildcards),用一种很短的文本模式(通常只有一个字符),简洁地代表一组路径。
通配符早于正则表达式出现,可以看作是原始的正则表达式。它的功能没有正则那么强大灵活,但是胜在简单和方便。
| 字 符 | 含 义 |
|---|---|
| * | 匹配0个或多个字符 |
| ** | 匹配任意级别目录(bash 4.0以上版本支持) |
| ? | 匹配任意一个字符 |
| [list] | 匹配list中的任意单一字符, 例如[abcd] 则表示一定由一个字符,可能是 a、b、c、d 中的任意一个 |
| [!list] | 匹配除list中的任意单一字符以外的字符 |
| [c1-c2] | 匹配c1-c2中的任意单一字符,如[0-9][a-z] |
| {string1, string2, ...} | 匹配string1或string2(或更多其一字符串) |
| {c1..c2} | 匹配c1-c2中的全部字符串 |
*.txt # 匹配全部后缀为.txt的文件
file?.log # 匹配file1.log, file2.log, ...
[ab].txt # 匹配 a.txt, b.txt
[a-z]*.log # 匹配a-z开头的.log文件
[^a-z]*.log # 上面的反向匹配
{a,b,c}.txt # 匹配a.txt, b.txt, c.txt
{j{p,pe}g,png} # 匹配 jpg jpeg png
~/**/*.conf # 匹配home目录下所有.conf文件
命令练习¶
Q1. 在home目录下创建自己名字命名的工作目录(如,zhangsan),进入该目录,然后再创建目录work1和work2,同时创建空文件test1.txt test2.txt。
mkdir zhangsan
cd zhangsan
mkdir work1
mkdir work2
touch test1.txt
touch test2.txt
ls -lh
Q2. 使用gzip压缩test1.txt文件,然后将压缩后的文件复制到work1目录下,最后在工作目录内目录内创建被压缩文件的软连接。
gzip test1.txt
ls -lh
cp test1.txt.gz work1
ln -s test1.txt.gz zhangsan.gz
Q3. 将当前目录下的test2.txt文件重命名,重命名后的文件为姓名首字母,如zs.txt。
mv test2.txt zs.txt
Q4. 将重命名后的文件zs.txt 移动到work2目录下,并将该文件权限改成700。
pwd
mv zs.txt work2/
chmod 700 work2/zs.txt
ls -lh work2/
Q5. 创建多层目录 1/2/3。
cd ~/zhangsan/
mkdir -p 1/2/3
Q6. 查找个人目录下所有以 gz 结尾的文件
cd ~/zhangsan/
find . -name "*gz"
Q7. 将 work1 目录 打包压缩成 work1.tar.gz,然后删除 work1 目录
tar -czvf work1.tar.gz work1
rm -rf work1
Q8. 将压缩包 work1.tar.gz 解压至 work2 中
pwd
tar -xzf work1.tar.gz -C work2
Q9. 统计工作目录下所有文件和目录的大小
cd ~/zhangsan/
du -sh *
Q10. 使用 tree 命令查看自己工作目录下的所有文件。
cd ~/zhangsan/
tree
文本操作¶
常用命令¶
- cat 打印输出文件内容, -A -n ;tac 反序输出
- less 分屏显示文件内容, -S –N
- more 类似less
- head 显示文件开头内容, -n 10; -n -10
- tail 显示文件尾部内容, -f -n 10; -n +10
- wc 文件内容计数 –l
- paste 多个文件按列合并
- sort 文件排序并输出 -k -n -r –t, 新版本的sort支持多线程排序
- uniq 显示重复行, 结合sort使用, -c –u
- diff 比较两个文件内容的异同
- tr 对输入字符进行替换 tr "ATCG" "TAGC"; tr 'A-Z' 'a-z'
- rev 逆序输出文件字符
- split 对文件进行拆分 -b –l
- cut 从文件每行提取字符 -d -f
- grep 文件内容搜索 -v -i -B -A -E -c -H
- zcat、zless、zmore、zgrep 对gzip压缩的文本做相应操作
- dos2unix windows格式文本换行成unix格式文本
- fold 把超过指定宽度的长行切成多行,默认宽度 80,常用于快速查看无换行的长序列/日志而不触发横向滚动
# 输出 'file' 文件的内容。一次输出文件全部内容,大文件请勿直接使用cat输出
$ cat file
a b 1
c d 2
f g 4
s g 3
# -n, 带行号
$ cat -n file
1 a b 1
2 c d 2
3 f g 4
4 s g 3
# -A, 打印特殊字符,比如换行符,制表键
$ cat -A file
a b 1$
c d 2$
f g 4$
s^Ig^I3$
# tac, 逆序输出文件内容,即先打印文件最后一行
$ tac file
s g 3
f g 4
c d 2
a b 1
# 分屏输出文件内容,默认只输出一屏内容
# 敲回车键,一行行显示后面的内容;
# f键,翻页显示
# 空格键:向下翻一页
# pagedown:向下翻一页
# pageup:向上翻一页
# /字符串:向下搜索字符串;注意这个斜杠也是需要输入的,不是在 「:」输入,:也和这个是一个功能
# ?字符串:向上搜索字符串
# n:重复前一个搜索(与 / 或 ?有关)
# N:反向的重复前一个搜索
# g:前进到这个资料的第一行
# G:前进到这个资料的最后一行去(注意是大写)
# q:离开 less 这个程序
$ less ref.fa
# -S, 不自动换行。less默认输出内容超过屏幕宽度会自动换行
$ less -S ref.fa
# -N, 添加行号
$ less -N ref.fa
# 输出文件前5行内容
$ head -n 5 num
1
2
3
4
5
# 输出除最后5行之外的内容
$ head -n -5 num
6
7
8
9
10
# 输出文件最后5行内容
$ tail -n 5 num
6
7
8
9
10
# 输出文件前5行之外的内容
$ tail -n +5 num
6
7
8
9
10
# 文件末尾有更新时,刷新更新内容
$ tail -f result
# 统计文件行数
$ wc -l num
10 num
$ cat file1
1
2
3
4
5
$ cat file2
a
b
c
d
e
# 按列合并两个文件,输出内容默认使用\t作为列之间的分隔符
$ paste file1 file2
1 a
2 b
3 c
4 d
5 e
$ cat file3
1
11
101
40
22
55
33
# 默认按照ASII码排序,对数字的排序与我们直观映像不同
$ sort file3
1
101
11
22
33
40
55
# -n, 按数字大小排序
$ sort -n file3
1
11
22
33
40
55
101
# -h, 按人可读的方式排序
$ sort -h file4
100
1K
1M
1G
# -k, 按指定的列排序
# 以第3列的数字排序
$ sort -nk3 file
w u 0
a b 1
c d 2
s g 3
# --parallel, 多线程
$ sort --parallel=4 file
# -T, 指定临时目录,默认为/tmp目录。对超大文件排序时,需要指定到本地,避免/tmp写满
$ sort -T ./mytem file
# -S, 指定内存。对超大文件需要限制内存使用,避免耗尽节点内存
$ sort -S 5G file
# -r, 逆序输出
$ sort -r
# 对genome.gtf文件先按染色体排序,然后再按位置排序
# sort -k1,4n genome.gtf 达不到所需要的效果,正确使用如下
$ sort -k1,1 -k4,4n genome.gtf
# 一般与sort 配合使用
# 显示重复行,并显示每个重复行的重复数
$ sort ref.fa |uniq -c
1 >chr10
99 NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNN
# 显示 file1和file2 2个文件内容的不同之处
$ diff file1 file2
# 碱基替换
$ echo "atctcctt"|tr "atcg" "tagc"
tagaggaa
# 大小写转换
$ echo "hello world"|tr 'a-z' 'A-Z'
HELLO WORLD
# 逆序输出
$ echo "hello world"|rev
dlrow olleh
# 碱基互补配对
$ echo "atctcctt"|tr "atcg" "tagc"|rev
aaggagat
# 将 'file' 文件拆分成10kb的小文件
$ split -b 10k file
# 将 'file' 文件拆分成每个只有10行的小文件
$ split -l 10 file
# -f 指定输出的列
# 输出文件第三列
$ cut -f2 genome.gff3|head -n5
gene
mRNA
mRNA
mRNA
mRNA
# -d 指定分隔符,默认为\t
# 输出csv文件的第三列
$ cut -d',' -f3 file.csv|head -n5
# 查找 'ref.fa' 文件中包含 "ACCC" 的行
$ grep "ACCC" ref.fa
# -v, 输出不匹配的行
# 查找 'ref.fa' 文件中不包含 "ACCC" 的行
$ grep -v "ACCC" ref.fa
# -i, 忽略大小写
# 查找 'ref.fa' 文件中包含 "ACCC" 的行,匹配时忽略大小写
$ grep -i "ACCC" ref.fa
# -c, 统计行数
# 查找 'ref.fa' 文件中包含 "ACCC" 的行的行数
$ grep -c "ACCC" ref.fa
# -e, 多模式匹配
# 查找 'ref.fa' 文件中包含 "ACCC" 或 "AGGG" 的行的行数
$ grep -e "ACCC" -e "AGGG" ref.fa
# -w, 匹配整词
# 匹配 word 而不匹配 words
$ grep -w 'word' file
# 查找 'ref.fa' 文件中包含 "ACCC" 的行,以及这行的前2行和后3行
$ grep -A2 -B3 "ACCC" ref.fa
# 打印文件 'file' 第3列
$ awk '{print $3}' file
# 提取文件 'file' 第1和3列,并用\t分隔
$ awk '{print $1"\t"$3}' file
$ awk 'print $1"\t"$3' file
# 打印文件 'file' 的倒数第二列
$ awk '{ print $(NF-1)}' file
# 将 'file' 文件中第三列相加求和
$ awk 'BEGIN{a=0}{a+=$3}END{print "Sum = ", a}' file
# 求第三列的平均值
$ awk 'BEGIN{a=0}{a+=$3}END{print "Average = ", a/NR}' file
# 求第三列的最大值
$ awk 'BEGIN {max = 0} {if ($3>max) max=$3 fi} END {print "Max=", max}' file
# 求第三列最小值
awk 'BEGIN {min = 1999999} {if ($1<min) min=$1 fi} END {print "Min=", min}' file
# 将 'genome.gff3' 文件中代表基因的行打印出来
$ awk '{if($3 == "gene" ){print $0}}' genome.gff3
$ awk '{if($3 == "gene" )print $0}' genome.gff3
# 将 'genome.gff3' 文件中代表基因、位于正链、且序列长度小于1000bp的行打印出来
$ awk '{if($3 == "gene" && $7 == "+" && ($5 -$4)<1000 ){print $0}}' genome.gff3
# 将 'file' 中的 gene 字符全部替换成 GENE
$ sed 's/gene/GENE/g' file
# 给 'file' 中每个单词加个中括号[]
$ sed 's/\w\+/[&]/g' file
# 删除 'file' 第2行
$ sed '2d' file
# 删除 'file' 中的空白行
$ sed '/^$/d' file
# 删除 'file' 中所有开头是test的行
$ sed '/^test/'d file
# 从1行开始,每隔3行插入>,并以行号为序列ID
$ sed '1~2 s/^/>\n/' example.fa|awk '{if($1 ~ />/){print $1NR}else{print $1}}' > example2.fa
# 格式化fa序列文件
fold -w 60 seq.fa > seq_60.fa
# 由于windows和linux中文本的换行符不同,windows下创建的文本在linux下直接使用可能会出错,需要进行格式转换
# windows格式文本换行成unix格式文本
$ dos2unix file
# 打印输出压缩文件
$ zcat file.gz
# 查看压缩文件
$ zless file.gz
# 搜索压缩文件中含字符串 aaaccc 的行
$ zgrep aaaccc file.gz
正则表达式¶
正则表达式(regular expression)是一些具体有特殊含义的符号,组合在一起的共同描述字符或字符串的方法。在 Linux 系统中,正则表达式通常用来对字符或字符串来进行处理,它是用于描述字符排列或匹配模式的一种语言规则。在grep/awk/sed中,经常需要使用正则表达式来处理文本。
https://man.linuxde.net/docs/shell_regex.html
| 正则表达式 | 描述 | 示例 |
|---|---|---|
| ^ | 匹配行开始 | 如:/^sed/匹配所有以sed开头的行 |
| $ | 匹配行结束 | 如:/sed$/匹配所有以sed结尾的行 |
| . | 匹配一个非换行符的任意字符 | 如:/s.d/匹配s后接一个任意字符,最后是d |
| * | 匹配0个或多个字符 | 如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行 |
| [] | 匹配一个指定范围内的字符 | 如/[ss]ed/匹配sed和Sed |
| [^] | 匹配一个不在指定范围内的字符 | 如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行 |
| .. | 匹配子串,保存匹配的字符 | 如s/loveable/\1rs,loveable被替换成lovers |
| & | 保存搜索字符用来替换其他字符 | 如s/love/*&*/,love这成**love** |
| \< | 匹配单词的开始 | 如:/\<love/匹配包含以love开头的单词的行 |
| > | 匹配单词的结束 | 如/love>/匹配包含以love结尾的单词的行 |
| x{m} | 重复字符x,m次 | 如:/0{5}/匹配包含5个0的行 |
| x{m,} | 重复字符x,至少m次 | 如:/0{5,}/匹配至少有5个0的行 |
| x{m,n} | 重复字符x,至少m次,不多于n次 | 如:/0{5,10}/匹配5~10个0的行 |
# 匹配含 gl,gf的行
$ grep "g[lf]" file
# 匹配输出序列名称行
$ grep ">.*" ref.fa
# 匹配输出含 google gooogle 的行
$ grep 'go\{2,3\}gl' file
# 删除所有开头是test的行
$ sed '/^test/'d file
# 删除含 google gooogle 的行
$ sed '/go\{2,3\}gl/d' file
# 只打印染色体
awk ' {if ($1 ~ /Chr/) print $0}' genome.gff
管道¶
管道命令(pipe)的作用,是将左侧命令的标准输出转换为标准输入,提供给右侧命令作为参数,使用 | 表示。同一行命令可以使用多个管道。使用管道可以省去很多中间文件
# 大小写转换
echo "hello world"|tr 'a-z' 'A-Z'
# 列出重复行
$ sort ref.fa |uniq -c
# 统计重复行
$ grep "gene" genome.gff|wc -l
# 打印压缩文件第一列
$ zcat genome.gff.gz |awk '{print $1}'
# 找出最常用的5个命令
$ history | awk '{print $2}' | sort | uniq -u | sort -rn | head -5
# 查看CPU型号
$ cat /proc/cpuinfo |grep name|cut -d : -f 2|uniq
# bwa比对后输出排序之后的bam文件
$ bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam
重定向¶
在shell交互环境下,默认的标准输入(standard input)和输出(standard output)是stdin和stdout,即键盘和屏幕:shell中运行的程序默认从键盘读取数据,默认将数据打印到屏幕上。 如果需要更改默认的输入和输出方向,则需要使用重定向功能。
数据重定向主要分为三类:
- stdin 表示标准输入,代码为0,使用<或<<操作符 : 符号<表示以文件内容作为输入 : 符号<<表示输入时的结束符号
- stdout 表示标准输出,代码为1,使用>或>>操作符 : 符号>表示以覆盖的方式将正确的数据输出到指定文件中 : 符号>>表示以追加的方式将正确的数据输出到指定文件中
- stderr 表示标准错误输出,代码为2,使用2>或2>>操作符 : 符号2>表示以覆盖的方式将错误的数据输出到指定文件中 : 符号2>>表示以追加的方式将错误的数据输出到指定文件中
# 取前100行生成新文件
$ head -n 100 file > new
# 提取 'genome.gff3' 中gene相关的部分生成新文件
$ awk '{if($3 == "gene" ){print $0}}' genome.gff3 > gene.gff3
# 将blast结果压缩
blastn -query ./ZS97_cds_10000.fa -db ./MH63_cds -outfmt 6 |gzip > ZS97_cds_10000.gz
# 将2个文件排序再按列合并,最后输出到新文件
$ paste <(sort file1 ) <(sort file2 ) > merge
# 将2个文件解压再按列合并,最后压缩输出到新文件
paste <(gzip -dc file1.gz ) <(gzip -dc file2.gz ) | gzip > merge.gz
# 将压缩文件作为输入
blastn -query <(gzip -dc ZS97_cds_10^6.fa.gz) -db ./MH63_cds -outfmt 6 |gzip > ZS97_cds_10000.gz
# 将fq文件转成fa
zcat ERR365991_1.fastq.gz |cat -n|awk '{if(NR%4 ==2) {n=int($1/4)+1;print ">"n"\n"$2}}' |gzip > reads.fa.gz
命令练习¶
Q1. 将文件 http://hpc.ncpgr.cn/data/seq.fa 下载至自己的目录下
cd ~/zhangsan/
wget http://hpc.ncpgr.cn/data/seq.fa
Q2. 使用 cat 查看 seq.fa 的内容
cat seq.fa
Q3. 使用 head 查看 seq.fa 前5行的内容
head -n5 seq.fa
Q4. 使用 tail 查看 seq.fa 后5行的内容
tail -n5 seq.fa
Q5. 使用 wc 统计 seq.fa 有多少行
wc -l seq.fa
Q6. 统计 seq.fa 中序列条数(即“>”开头的行数)
cat seq.fa|grep ">"|wc -l
Q7. 使用 grep 和 awk 筛选出 seq.fa 中的序列名称而不要描述部分
cat seq.fa|grep ">"|awk '{print $1}'
Q8. 将 seq.fa 中小写的碱基序列 atcg 换成大写的 ATCG,序列名称中的字母不变,结果输出到新的序列文件中 seq1.fa
sed -e '/^>/!s/[atcg]/\U&/g' seq.fa > seq1.fa
Q9. 计算这段序列的反向互补配对的序列 TTTTGAGTGGTGAAAGGTGAGAGGAATAGGAGTAAAAATGTGT
echo 'TTTTGAGTGGTGAAAGGTGAGAGGAATAGGAGTAAAAATGTGT'|tr 'ATCG' 'TAGC'|rev
Q10. 使用 awk 计算 seq.fa 中所有序列行的总碱基数(不含标题行)。
awk '!/^>/ {sum+=length} END {print sum}' seq.fa
Q11. 统计 seq.fa 中碱基出现次数
# 一行超长序列拆成单字符
grep -v '^>' seq.fa | fold -w1 | sort | uniq -c
Q12. 将文件 ~/data/genome.gff.gz 拷贝至自己的目录下然后解压为 genome.gff
cd ~/zhang/
cp ~/data/genome.gff.gz .
gzip -d genome.gff.gz
Q13. 统计 genome.gff 中有多少个基因
# 统计文件第3列为 gene 的数量
awk '$3=="gene"' genome.gff |wc -l
Q14. 将 genome.gff3 文件中代表基因、位于正链、且序列长度小于2000bp的行打印出来
awk '{if($3 == "gene" && $7 == "+" && ($5 -$4)<2000 ){print $0}}' genome.gff
vim¶
Linux下常用的文本编辑器,键盘操作,功能丰富,高度定制, 无数插件, 无限创(zheng)意(teng)
三种模式: 正常模式, 插入模式, 命令模式
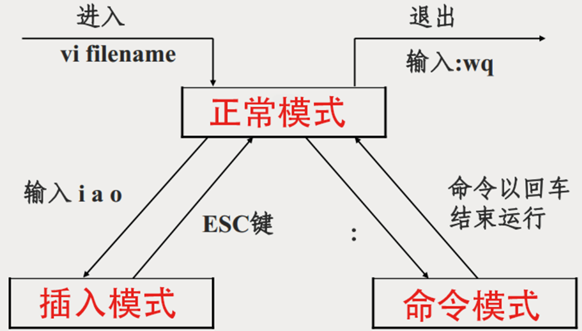
vim filename 打开或新建文件,并将光标置于第一行首
常用操作¶
插入模式下执行
i: 在光标前a: 在光标后o: 在下一行新开一行O: 在上一行新开一行backspace/del键: 删除前后字符
正常模式下执行
j或↓: 光标下移k或↑: 光标上移h或←: 光标左移l或→: 光标右移^: 光标移至行首$: 光标移至行尾G: 光标移至文本最后一行数字+G: 光标移至指定的行ctrl+g: 光标跳到上次的行gg: 光标移至文本第一行回车键: 光标移至下一行ctrl+f: 向下翻页ctrl+b: 向上翻页
正常模式下执行
x: 删除光标后一个字符X: 删除光标前一个字符dd: 删除当前行- 在插入模式下可以使用backspace/del键删除字符
u: 撤销操作(类似于word中的ctrl+z)ctrl+r: 撤销u的操作,即回来撤销之前(类似于word中的ctrl+y)
正常模式下执行
v: 移动光标,选择复制范围; 再按v,取消选择V: 上下移动光标,选择整行; 再按V,取消选择ctrl+v: 上下移动光标,选择文本块; 选择特定的列; 再按ctrl+v,取消选择
正常模式下执行
y: 复制,配合选择命令,可以实现复制部分文本p: 在光标后粘贴复制内容yy: 复制整行
命令模式下执行
:w保存修改:wq保存退出(也可以在正常模式下用ZZ代替):!q强制退出:set nu显示文本行号:file显示当前文本文件名:1,$s/hello/HELLO/g将整个文本中的hello替换成HELLO:!ls执行linux命令,如ls
正常模式下执行
ctrl+w s: 水平分割ctrl+w v: 垂直分割ctrl+w hjkl: 在不同窗口间移动
参考: vim自动格式化对齐代码
正常模式下执行
==: 对光标所在行进行自动格式化对齐,会根据代码情况增加或减少缩进。可以在==前面加上数字,指定要同时处理多少行。例如,4==会格式化对齐当前行、以及后面的三行gg=G: 对整个文件都重新格式化对齐
ctrl + x -> ctrl +n: 通过目前正在编辑的这个「文件的内容文件」作为关键词,补齐;ctrl + x -> ctr + f: 以当前目录内的「文件名」作为关键词,予以补齐ctrl + x -> ctrl + o: 以扩展名作为语法补充,以 vim 内置的关键词,予以补齐
基本设置¶
在命令模式下可以对vim进行个性化设置,如显示行号、高亮当前行等,常见设置如下:
| 设置 | 含义 |
|---|---|
| :set nu、:set nonu | 设置与取消行号 |
| :set hlsearch、:set nohlsearch | hlsearch 是 high light search (高亮度搜索)。设置是否将搜索到的字符串反白设置。默认为 hlsearch |
| :set autoindent、:set noautoindent | 是否自动缩排?当你按下 Enter 编辑新的一行时,光标不会在行首,而是在于上一行第一个非空格符处对齐 |
| :set backup | 是否自动存储备份文件,一般是 nobackup 的,如果设置为 backup,那么当你更改任何一个文件时,则源文件会被另存一个文件名为 filename~ 的文件。如:编辑 hosts,设置 :set backup ,那么修改 hosts 时,在同目录下就会产生 hosts~ 的文件 |
| :set ruler | 右下角的状态栏说明,是否显示或不显示该状态的显示 |
| :set shwmode | 是否要显示 ---INSERT-- 之类的提示在左下角的状态栏 |
| :set backpace=(012) | 一般来说,如果我们按下 i 进入编辑模式后,可以利用退格键(baskpace)来删除任意字符的。但是某些 distribution 则不允许如此。此时,可以通过 backpace 来设置,值为 2 时,可以删除任意值;0 或 1 时,仅可删除刚刚输入的字符,而无法删除原本就已经存在的文字 |
| :set all | 显示目前所有的环境参数设置 |
| :syntax on 、 :syntax off | 是否依据程序相关语法显示不同颜色 |
| :set bg=dark、:set bg=light | 可以显示不同颜色色调,预设是 light。如果你常常发现批注的字体深蓝色是在很不容易看,就可以设置为 dark |
| :set cursorline | 高亮显示当前行,当前行显示一条长线 |
常用设置也可写入 ~/.vimrc 中
$ cat ~/.vimrc
" 该文件的注释是使用双引号表达
set hlsearch "高亮度反白
set backspace=2 "可随时用退格键删除
set autoindent "自动缩进
set ruler "可现实最后一列的状态
set showmode "左下角那一列的状态
set nu "在每一行的最前面显示行号
set bg=dark "显示不同的底色色调
syntax on "进行语法检验,颜色显示
set cursorline "高亮显示当前行,当前行显示一条长线
# 保存后,再次打开最明显的就是自动显示行号了,可见是生效了的
插件¶
利用vim插件可以实现更多功能和酷炫的效果,见 Vim 常用插件 & 插件管理
命令练习¶
Q1. 创建文件me.txt,使用 vim 打开 me.txt,然后输入以下内容
i am zhangsan
i am learning linux
Q2. 在vim中复制第2行内容,并将其粘贴5次
Q3. 将所有的am leaning 删除,并更改为 love
Q4. 删除最后2行
进程管理¶
进程(process)即运行中的程序,同一个程序可以有多个进程在运行。
PID :进程 ID, 每个进程都会从内核获取一个唯一的 ID 值。
作为用户需要了解自己正在跑的进程,用了多少CPU资源、内存等,知道怎么杀死进程、挂起进程、在后台跑程序、长期稳定地跑程序等。
$ top
top - 09:13:17 up 129 days, 17:21, 1 user, load average: 32.10, 27.60, 25.74
Tasks: 462 total, 9 running, 453 sleeping, 0 stopped, 0 zombie
%Cpu(s): 90.0 us, 5.5 sy, 0.0 ni, 4.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 39570169+total, 15617606+free, 23756960+used, 1956012 buff/cache
KiB Swap: 4194300 total, 2389376 free, 1804924 used. 15288067+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
55164 user1 20 0 1191524 667856 2284 S 774.8 0.2 9:26.29 hisat2-align-s
18252 user2 20 0 22.8g 19.3g 1020 R 599.7 5.1 1458:45 overlapInCore
446439 user2 20 0 22.7g 19.2g 1020 R 599.7 5.1 2487:18 overlapInCore
9442 user2 20 0 22.9g 19.3g 1020 R 599.3 5.1 1754:11 overlapInCore
13186 user2 20 0 22.7g 19.2g 1024 R 599.3 5.1 1633:27 overlapInCore
53033 user3 20 0 69.1g 67.9g 1948 R 100.0 18.0 14:23.56 fastlmmc
53415 user3 20 0 69.4g 68.4g 1956 R 99.7 18.1 12:31.07 fastlmmc
55166 user1 20 0 4756 656 472 S 21.6 0.0 0:15.62 gzip
55165 user1 20 0 4756 660 472 R 20.3 0.0 0:14.64 gzip
55162 user1 20 0 137112 4268 596 R 8.0 0.0 0:05.83 perl
55163 user1 20 0 137112 4268 596 S 8.0 0.0 0:05.70 perl
29589 root 0 -20 25.6g 6.9g 2.3g S 1.7 1.8 8821:57 mmfsd
47500 root 0 -20 40136 8384 1392 S 0.3 0.0 93:21.17 lim
55383 root 20 0 166508 2760 1676 R 0.3 0.0 0:00.02 top
1 root 20 0 54424 3120 1568 S 0.0 0.0 27:26.10 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:09.81 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 2:47.41 ksoftirqd/0
8 root rt 0 0 0 0 S 0.0 0.0 0:43.65 migration/0
9 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
10 root 20 0 0 0 0 S 0.0 0.0 122:40.09 rcu_sched
11 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
12 root rt 0 0 0 0 S 0.0 0.0 0:22.52 watchdog/0
前台任务与后台任务¶
"前台任务"(foreground job)是独占命令行窗口的任务,只有运行完了或者手动中止该任务,才能执行其他命令。如果没有特殊操作,一般用户执行的命令为前台任务。
"后台任务"(background job)通常在不打扰用户其它工作的时候默默地执行(此时可以输入其他的命令)。其特点为:
- 继承当前session(对话)的标准输出(stdout)和标准错误(stderr)。因此,后台任务的所有输出依然会同步地在命令行下显示。
- 不再继承当前session的标准输入(stdin)。你无法向这个任务输入指令了。如果它试图读取标准输入,就会暂停执行(halt)。
可以看到,"后台任务"与"前台任务"的本质区别只有一个:是否继承标准输入。所以,执行后台任务的同时,用户还可以输入其他命令。使用nohup, &, bg, diwown, screen 等命令可让命令在后台运行。
常用命令¶
- top 动态显示系统运行状况 M c
- ps 输出系统所有进程状态 ps aux
- kill 杀死进程或作业 kill –s 9 18 19 -u
- killall 杀死指定名称的进程
- pgrep 查找进程
- nohup 将程序挂起运行, 账号退出不受影响, 一般和&配合使用
- disown 使已经在运行的用户进程 不受用户退出限制
- jobs 查看任务运行状态
- bg 将作业放在后台运行, 与&类似; fg, 将作业放在前台运行
- screen 命令行终端切换软件 -s -ls -d -r; 可尝试更强大的tmux
- & 将程序放后台运行
- Ctrl+z 暂停前台运行作业; Ctrl+c, 杀死前台运行的作业
- time 统计命令运行时间
# 查看当前系统运行的进程,每几秒刷新一次
# M 按进程使用内存排序
# c 查看进程的运行参数
# u 查看指定用户的进程
# q 退出
$ top
top - 09:13:17 up 129 days, 17:21, 1 user, load average: 32.10, 27.60, 25.74
Tasks: 462 total, 9 running, 453 sleeping, 0 stopped, 0 zombie
%Cpu(s): 90.0 us, 5.5 sy, 0.0 ni, 4.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 39570169+total, 15617606+free, 23756960+used, 1956012 buff/cache
KiB Swap: 4194300 total, 2389376 free, 1804924 used. 15288067+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
55164 user1 20 0 1191524 667856 2284 S 774.8 0.2 9:26.29 hisat2-align-s
18252 user2 20 0 22.8g 19.3g 1020 R 599.7 5.1 1458:45 overlapInCore
446439 user2 20 0 22.7g 19.2g 1020 R 599.7 5.1 2487:18 overlapInCore
9442 user2 20 0 22.9g 19.3g 1020 R 599.3 5.1 1754:11 overlapInCore
13186 user2 20 0 22.7g 19.2g 1024 R 599.3 5.1 1633:27 overlapInCore
53033 user3 20 0 69.1g 67.9g 1948 R 100.0 18.0 14:23.56 fastlmmc
53415 user3 20 0 69.4g 68.4g 1956 R 99.7 18.1 12:31.07 fastlmmc
# 输出系统所有进程
$ ps aux
# 根据cpu使用率进行排序
ps -aux --sort -pcpu | less
# 根据内存使用来升序排序
ps -aux --sort -pmem | less
# 杀死进程id(pid)为14234的进程
$ kill 14234
# 强制杀死进程,使用信号9
$ kill -s 9 14234
# 挂起进程,即让进程暂停运行,但不杀掉进程。使用信号19
$ kill -s 19 14234
# 恢复被挂起的进程,即让被暂停的进程恢复运行。使用信号18
$ kill -s 18 14234
# 杀死bwa进程
$ killall bwa
# 杀死用户username的所有进程
$ killall -u username
# 查找所有bwa进程,返回进程id
$ pgrep bwa
9442
13186
18252
446439
# 将bwa放前台运行
$ bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam
# CTRL-z挂起
$ ^Z
[1]+ Stopped bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam
# 放在后台
$ bg %1
[1]+ bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam &
# 查看后台任务
$ jobs
[1]+ Running bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam &
# 将bwa放后台运行,即使远程ssh退出也不影响bwa运行
$ nohup bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam &
# 查看后台任务状态
$ jobs
[1] Running sleep 60 &
[2] Running sleep 60 &
$ jobs
[1] Done sleep 60
[2] Done sleep 60
# 程序在前台运行了一段时间,在不杀掉程序重跑的情况下,将前台作业变为后台作业
# 不放在后台的命令
$ bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam
# CTRL-z挂起
$ ^Z
[1]+ Stopped bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam
# 放在后台
$ bg %1
[1]+ bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam &
# 查看后台任务
$ jobs
[1]+ Running bwa mem -t 8 genome.fa read1.fq.gz read2.fq.gz | samtools sort -@8 -o output_sorted.bam &
# 再使用disown命令
$ disown -h %1
# 查看进程
$ ps -aux |grep bwa
# 在Screen环境下,所有的会话都独立的运行,并拥有各自的编号、输入、输出和窗口缓存。
# 用户可以通过快捷键在不同的窗口下切换,并可以自由的重定向各个窗口的输入和输出。Screen实现了基本的文本操作,如复制粘贴等;
# 还提供了类似滚动条的功能,可以查看窗口状况的历史记录。窗口还可以被分区和命名,还可以监视后台窗口的活动。
# 会话共享 Screen可以让一个或多个用户从不同终端多次登录一个会话,并共享会话的所有特性(比如可以看到完全相同的输出)。
# 它同时提供了窗口访问权限的机制,可以对窗口进行密码保护。
# 新建名为bwa的session
$ screen -S bwa
# 列出所有的session
$ screen -ls
# 远程detach bwa的session
# 在当前这个screen窗口中时,可用ctrl+a ctrl+a 来detach当前session
$ screen -d bwa
# 回到bwa这个session
$ screen -r bwa
# screen配置
$ cat ~/.screenrc
# 显示状态栏,方便区分不同的screen session
hardstatus on
hardstatus alwayslastline
hardstatus string "%{= kw}%-w%{= kG}%{+b}[%n %S %t]%{-b}%{= kw}%+w %=[%Y-%m-%d %c]%{g}%{-}"
# 支持鼠标上下滚动
termcapinfo xterm ti@:te@
# 默认使用bash内置time命令,输出程序运行时间
$ time grep -f file.txt parttern.txt
real 3m3.760s
user 2m47.634s
sys 0m15.635s
# 也可以使用外部time程序 /usr/bin/time
# /usr/bin/time -v 输出各种资源消耗
# \time -v 也可以代替
# time -v 会报错
$ /usr/bin/time -v grep -f file.txt parttern.txt
# /usr/bin/time -f 可指定输出的资源,有多种选项可以使用
# 如 -f "%e %p %M" 可输出程序运行时间(s)、CPU使用占比、最大使用内存(kb)
$ /usr/bin/time -f "%e %P %M" grep -f file.txt parttern.txt
178.44 99% 17553368
# 可以使用alias改写time,或设置TIME环境变量设置time命令输出格式
$ alias time="$(which time) -f '%E real,\t%U user,\t%S sys,\t%K amem,\t%M mmem'"
0:16.89 real, 16.46 user, 0.38 sys, 0 amem, 458512 mmem
$ export TIME='%E real,\t%U user,\t%S sys,\t%t amem,\t%M mmem'
$ /usr/bin/time grep -f file.txt parttern.txt > xxx
0:17.26 real, 16.79 user, 0.41 sys, 0 amem, 457092 mmem
系统信息查看¶
使用Linux系统提供的工具和命令查看磁盘使用、系统负载、内存使用、系统版本等信息。
常用命令¶
- df 显示系统磁盘使用情况 -h
- free 显示系统内存使用情况 -h
- ip 显示系统IP配置
- lscpu 查看CPU配置 lscpu
- lsb_release 查看操作系统版本 -a
- uname 内核版本 -a
- lspci 查看PCI设备,CPU、GPU、网卡等
- uptime 查看系统运行时间、负载信息
- top 查看系统负载等信息
- who 查看登录用户
# 查看/public目录磁盘使用情况
$ df -h /public
Filesystem Size Used Avail Use% Mounted on
public 5.5P 4.3P 1.3P 78% /public
# 查看内存使用情况
$ free -g
total used free shared buff/cache available
Mem: 93 66 12 4 15 16
Swap: 0 0
# 查看IP地址
$ ip a
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 10
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 5115 CPU @ 2.40GHz
Stepping: 4
CPU MHz: 2400.000
BogoMIPS: 4800.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 14080K
NUMA node0 CPU(s): 0-9,20-29
NUMA node1 CPU(s): 10-19,30-39
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 intel_ppin intel_pt mba tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local ibpb ibrs stibp dtherm ida arat pln pts hwp_epp pku ospke spec_ctrl intel_stibp
# 查看系统版本, 也可使用 cat /etc/redhat-release。不同linux发行版本查看方式略有不同。
$ lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch:cxx-4.1-amd64:cxx-4.1-noarch:desktop-4.1-amd64:desktop-4.1-noarch:languages-4.1-amd64:languages-4.1-noarch:printing-4.1-amd64:printing-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 7.5.1804 (Core)
Release: 7.5.1804
Codename: Core
$ cat /etc/redhat-release
CentOS Linux release 7.5.1804 (Core)
# 查看操作系统内存版本
$ uname -a
Linux localhost 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
# 查看系统运行时间和负载
$ uptime
11:11:42 up 69 days, 23:25, 200 usergroup, load average: 6.10, 8.08, 6.46
# 查看系统负载、内存消耗、进程运行情况
$ top
top - 09:13:17 up 129 days, 17:21, 1 user, load average: 32.10, 27.60, 25.74
Tasks: 462 total, 9 running, 453 sleeping, 0 stopped, 0 zombie
%Cpu(s): 90.0 us, 5.5 sy, 0.0 ni, 4.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 39570169+total, 15617606+free, 23756960+used, 1956012 buff/cache
KiB Swap: 4194300 total, 2389376 free, 1804924 used. 15288067+avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
55164 user1 20 0 1191524 667856 2284 S 774.8 0.2 9:26.29 hisat2-align-s
18252 user2 20 0 22.8g 19.3g 1020 R 599.7 5.1 1458:45 overlapInCore
446439 user2 20 0 22.7g 19.2g 1020 R 599.7 5.1 2487:18 overlapInCore
9442 user2 20 0 22.9g 19.3g 1020 R 599.3 5.1 1754:11 overlapInCore
13186 user2 20 0 22.7g 19.2g 1024 R 599.3 5.1 1633:27 overlapInCore
53033 user3 20 0 69.1g 67.9g 1948 R 100.0 18.0 14:23.56 fastlmmc
53415 user3 20 0 69.4g 68.4g 1956 R 99.7 18.1 12:31.07 fastlmmc
# 查看登录用户
$ who
user1 pts/0 2021-09-17 08:49 (192.168.1.31)
user2 pts/1 2021-09-16 11:51 (192.168.1.32)
user3 pts/2 2021-09-17 14:22 (192.168.1.33)
user4 pts/3 2021-09-17 18:22 (192.168.1.34)
user5 pts/5 2021-09-16 23:32 (192.168.1.35)
user6 pts/6 2021-09-17 17:38 (192.168.1.36)
命令练习¶
Q1. 列出当前节点登录的用户并去重排序后将其写入 user_list.txt 文件中
who|awk '{print $1}'|sort |uniq > user_list.txt
简单shell编程¶
shell可以理解为一种脚本语言,只需要一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以。
shell脚本的本质是组合Linux命令, 变量, 数据结构,逻辑语句和for while if 等流程控制语句,由shell程序解析执行的脚本文本文件。
第一个shell脚本 test.sh
#!/bin/bash
echo "Hello World !"
chmod +x ./test.sh #使脚本具有执行权限
./test.sh #执行脚本
变量¶
普通变量:
# 3种定义变量的方式
# 最常见的变量定义方式
$ string="this is a string"
# 将ls /home/的输出存储到变量file中
$ file=$(ls /home/)
# 将cat file的输出存储到变量text中
$ text=`cat file`
# 使用变量,$string或${string}
echo "${string}, ${file}"
环境变量:$PWD, $HOME, $PATH ...,env 命令可以打印所有环境变量
脚本传参变量:$1 $2 ...
运算符¶
逻辑运算符
| 操作符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] 返回 false |
| || | 逻辑的 OR | [[ $a -lt 100 || $b -gt 100 ]] 返回 true |
#!/bin/bash
a=10
b=20
if [[ $a -lt 100 && $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fi
if [[ $a -lt 100 || $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fi
| 操作符 | 说明 | 举例 |
|---|---|---|
| -d file | 检测文件是否是目录,如果是,则返回 true。 | [ -d $file ] 返回 false。 |
| -f file | 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 | [ -f $file ] 返回 true。 |
| -r file | 检测文件是否可读,如果是,则返回 true。 | [ -r $file ] 返回 true。 |
| -w file | 检测文件是否可写,如果是,则返回 true。 | [ -w $file ] 返回 true。 |
| -x file | 检测文件是否可执行,如果是,则返回 true。 | [ -x $file ] 返回 true。 |
| -s file | 检测文件是否为空(文件大小是否大于0),不为空返回 true。 | [ -s $file ] 返回 true。 |
| -e file | 检测文件(包括目录)是否存在,如果是,则返回 true。 | [ -e $file ] 返回 true。 |
#!/bin/bash
file="/home/user/test.sh"
if [[ -f $file && -x $file ]]
then
echo "文件可执行"
fi
流程控制¶
#!/bin/bash
if [[$1 == "memory" ]]
then
free -m
else
lscpu
fi
#!/bin/bash
for i in node{1..10}
do
echo ${i}
ssh ${i} "free -g"
done
#!/bin/bash
file=/etc/hosts
while read line
do
echo ${line}
done < "$file"
调试¶
sh [-nvx] scripts.sh
选项与参数:
-n:不执行 script,仅检查语法问题
-v:执行 script 前,先将 scripts 内容输出到屏幕上
-x:将执行到的 script 内容显示到屏幕上,相当于 debug 了
综合¶
#!/bin/sh
fa=""
cat file.fa|while read line;do
if [[ ${line} =~ \> ]];then
echo ${line}
echo ${fa}|tr "ATCG "TAGC"|rev
fa=""
else
fa=${fa}${line}
fi
done
#!/bin/sh
cd $PWD
thread=5
for sample in ${HOME}/exercise/raw_data/*trim_1.fq.gz;do
index=$(basename $sample|sed 's/_trim_1\.fq\.gz//')
dir=$(dirname $sample)
if [[ -f $dir/${index}_trim_1.fq.gz && -f $dir/${index}_trim_1.fq.gz ]] ;then
#align
hisat2 -x ${HOME}/exercise/genome/reference \
-1 $dir/${index}_trim_1.fq.gz -2 $dir/${index}_trim_2.fq.gz -p ${thread} -S ${index}.sam
#sam2bam
samtools view -bs ${index}.sam > ${index}.bam
#sort bam
samtools sort -@${thread} ${index}.bam ${index}_sort.bam
#rm sam bam
rm ${index}.bam ${index}.sam
#assembly
stringtie ${index}_sort.bam -G ${HOME}/exercise/genome/reference.gtf \
-o ${index}.gtf -p ${thread}
#stat
transcript_stat.pl ${index}.gtf > ${index}_stat
fi
done
命令练习¶
Q1. 列出当前目录下所有文件和目录,并判断其是否为普通文件,是返回 filename is a file,否则返回 filename is not a file。
#!/bin/bash
for item in `ls`; do
if [[ -f "$item" ]]; then
echo "$item is a file"
else
echo "$item is not a file"
fi
done
参考资料¶
https://biohpc.cornell.edu/lab/doc/Linux_exercise_part1.pdf
https://sites.ualberta.ca/~stothard/downloads/linux_for_bioinformatics.pdf
UC Davis Bioinformatics Core Training Page
Getting Started with scRNA-Seq Seminar Series
本文阅读量 次本站总访问量 次